MiniMax Sparse Attention (MSA): a Two-Branch Block-Sparse Attention Trained on a 109B-Parameter MoE With a …
What changed
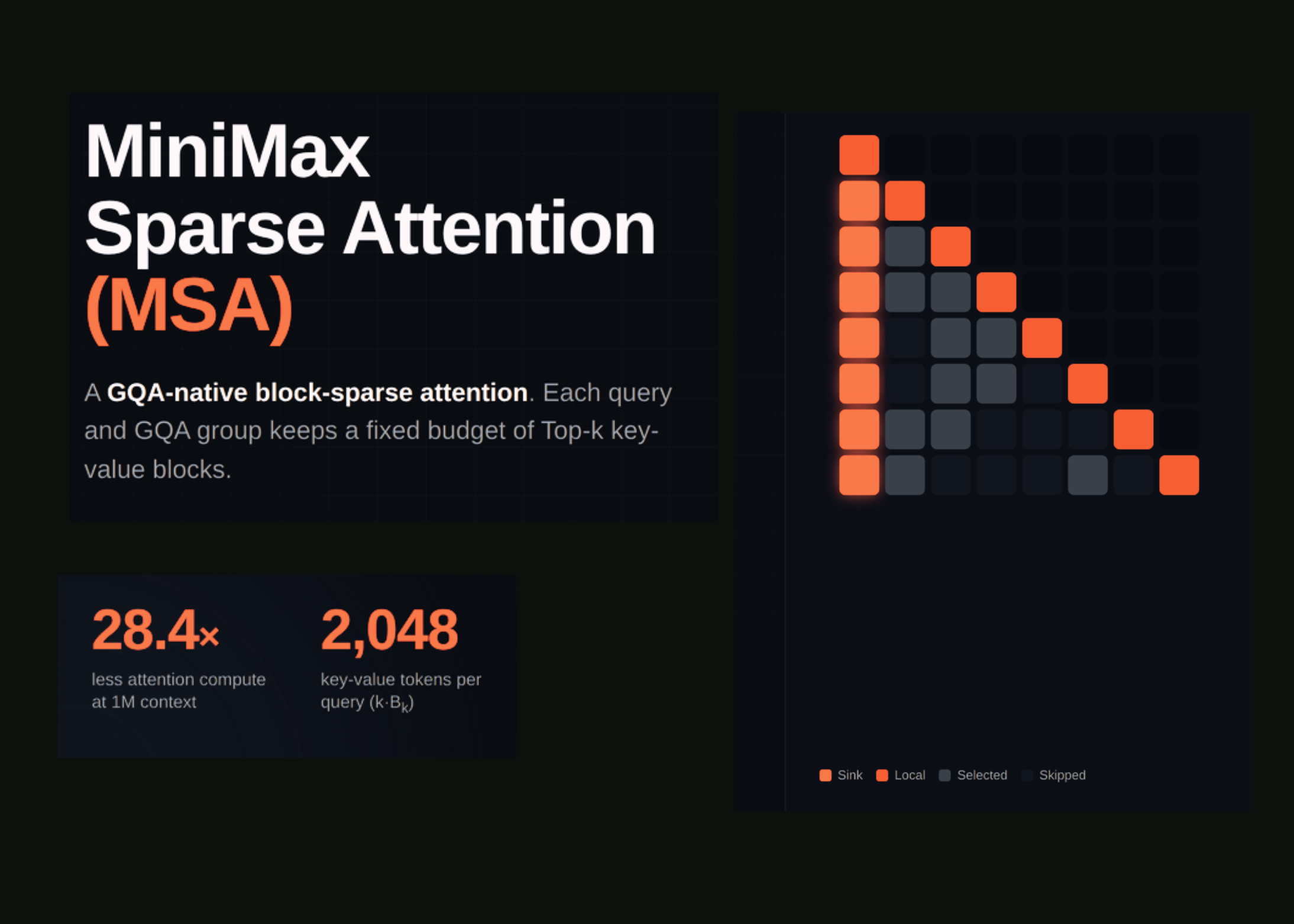
MiniMax introduced MiniMax Sparse Attention (MSA), a two-branch block-sparse attention mechanism built on Grouped Query Attention (GQA). The design uses an Index Branch that lightly scans to select the top key-value blocks relevant per query and GQA group. The Main Branch then focuses its attention only on those selected blocks. This method was trained on a massive 109 billion-parameter Mixture-of-Experts (MoE) model using a 3 trillion-token training budget. MSA delivers a 28.4 times reduction in per-token attention compute compared to full attention at a 1 million token context window, while matching GQA’s performance on downstream benchmarks.
Why builders should care
The big deal here is the scalability and efficiency of handling extremely long context windows on massive models. Traditional attention scales quadratically with sequence length, making very long documents or conversations costly in compute and memory. MSA’s two-branch approach drastically cuts down computations without losing model accuracy on key tasks. This addresses a critical bottleneck that hinders training and deployment of large models for complex, long-context use cases like document understanding, code generation, or multi-turn dialogue at scale.
The practical takeaway
Operators and developers building or scaling LLM-based systems can now consider block-sparse attention as a viable alternative to full attention for very long sequences. This can lower GPU memory pressure and reduce inference and training costs significantly. Since MiniMax matched GQA’s downstream quality, switching to MSA potentially lets teams handle bigger context lengths or more tokens per dollar spent, which improves operational efficiency and end-user experience. It also suggests that sparsity methods continue evolving beyond simple pruning toward intelligent dynamic block selection tied to model attention patterns.
What to watch next
Focus will be on how MiniMax’s sparse attention competes with other popular long-context optimizations like FlashAttention, Performer, or BigBird implementations—especially in real-world settings. It will be important to see how accessible this tech becomes outside research labs and whether open source frameworks quickly adopt or incorporate MSA principles. Finally, the influence of training on a 109B MoE at a 3T-token scale raises questions about necessary infrastructure investments to replicate or build on this work for commercial and research teams.
AI Quick Briefs Editorial Desk


