NVIDIA AI Releases Nemotron 3 Ultra: An Open 550B Mixture-of-Experts Hybrid Mamba-Transformer for Long-Runn…
What it does
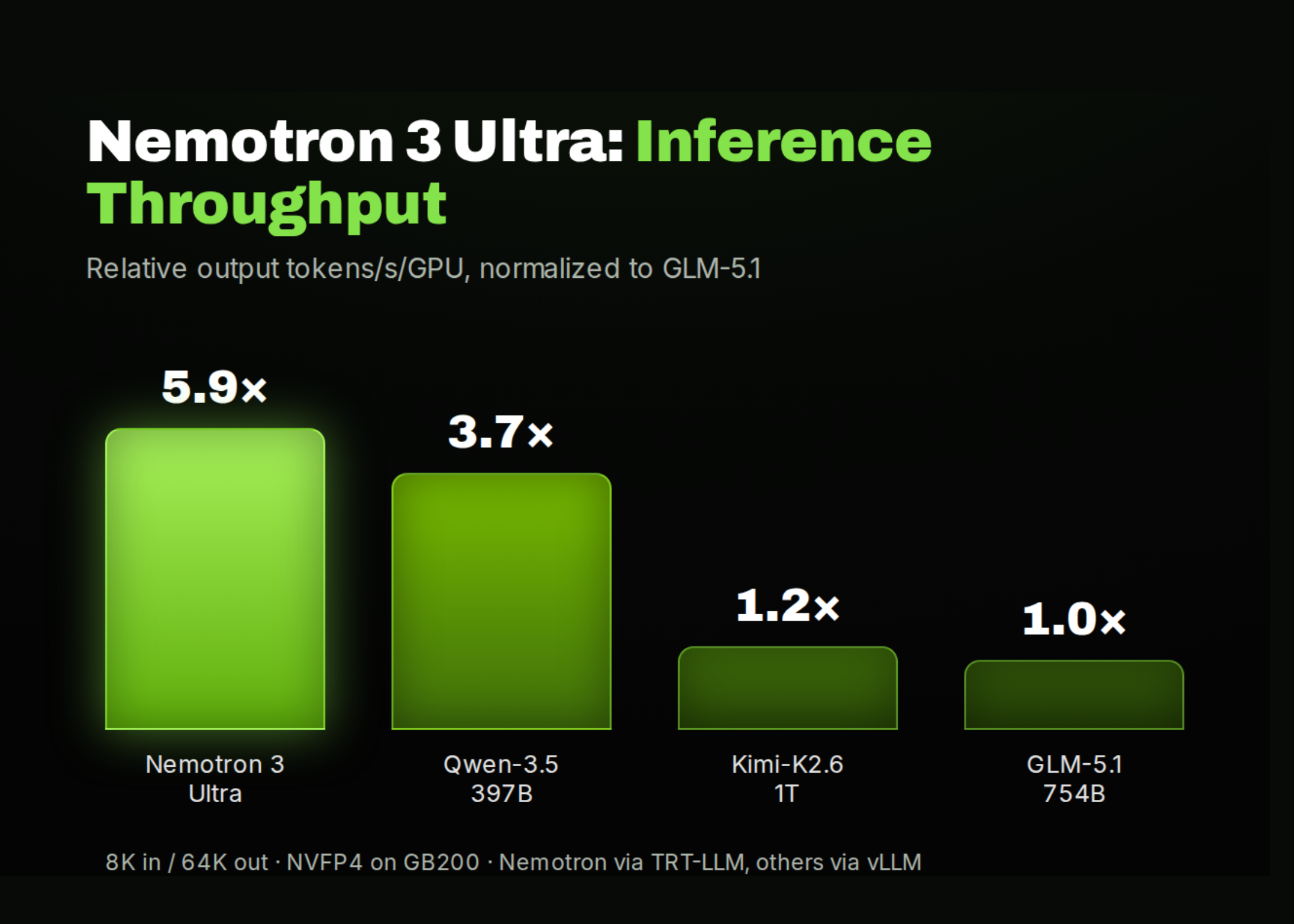
NVIDIA launched Nemotron 3 Ultra, an open large language model built as a hybrid Mamba-Transformer using a 550 billion parameter Mixture-of-Experts design. Of those, 55 billion parameters are actively engaged during inference. The model supports a massive 1 million token context window, which addresses the challenge of long context retention for extended agent tasks. NVIDIA claims Nemotron 3 Ultra achieves roughly six times the inference throughput compared to similar open LLMs while maintaining comparable accuracy. The release includes open weights, training data, and recipes under an OpenMDW-1.1 license.
Why it matters
Nemotron 3 Ultra pushes the boundaries of what open source generative AI models can handle in terms of context length and throughput, addressing two major bottlenecks for real-world deployment of long-running agents. The sheer size of the model combined with selective activation of experts keeps compute down without compromising output quality. Higher throughput means faster responses and better cost-efficiency for businesses deploying agents requiring deep memory or complex multi-turn reasoning. Open release of weights and training materials means operators and researchers gain practical access to a model that previously only large tech players could afford to train or run.
Who it is for
This model is geared towards AI builders and operators developing agents for applications demanding extended context tracking, like customer support bots, multi-session assistants, or workflow automation tools that rely on sustained interaction histories. It also targets researchers and organizations that need scalable, open architectures to experiment with Mixture-of-Experts models without prohibitive licensing or black-box limitations. Enterprises benefiting from faster, cheaper inference will find it a way to deliver richer AI capabilities in production scenarios cost-effectively.
The catch
While NVIDIA offers improved throughput and massive context handling, the model still requires substantial hardware resources to operate efficiently, especially at 550 billion parameters. Active parameters at 55 billion help, but running Nemotron 3 Ultra is far from low-cost or accessible for casual users or small businesses without GPU infrastructure. Also, open weights bring transparency but raise operational risks around fine-tuning, misuse, and model governance—operators must prepare for responsible deployment.
What to watch next
Watch for how the ecosystem around Nemotron 3 Ultra evolves, including fine-tuning pipelines, toolkits for efficient deployment, and third-party service integrations. Pay attention to competing open LLM projects addressing long context and throughput, as the cost and performance gains here could reset expectations for scalable AI agents. Monitor NVIDIA’s follow-up releases on model variants or infrastructure optimizations, as well as adoption by cloud and AI system vendors aiming to build agent platforms on top of Nemotron 3 Ultra.
AI Quick Briefs Editorial Desk