Salesforce CodeGen Tutorial: Generate, Validate, and Rerank Python Functions With Unit Tests and Safety Checks
What changed
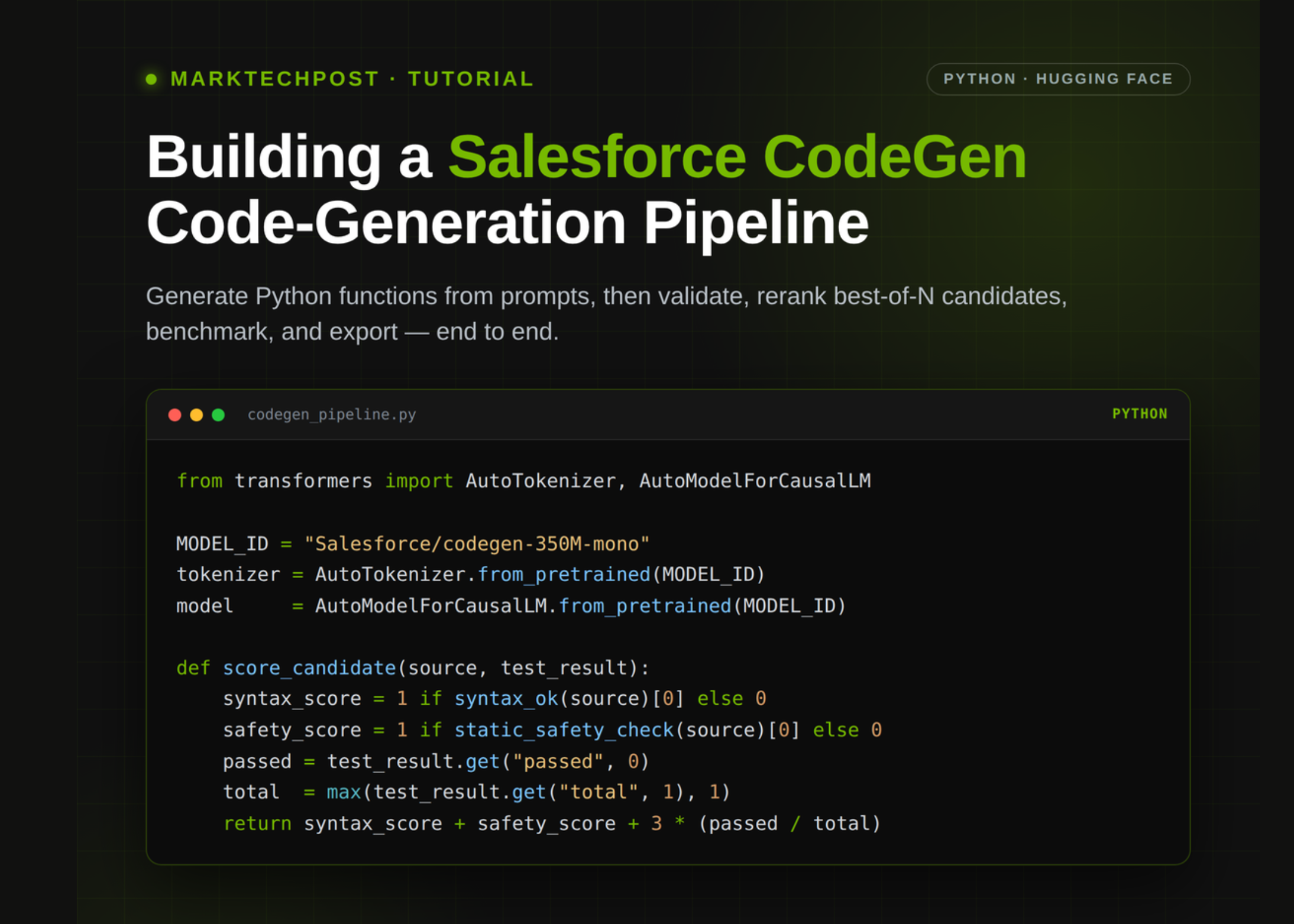
Salesforce CodeGen’s Python function generation has been extended beyond basic code output. The new workflow pulls CodeGen models from Hugging Face and adds an infrastructure to extract generated functions, check their syntax, apply static safety filters, and run unit tests. It also reranks multiple candidate solutions based on test validation and safety criteria. The pipeline supports multi-turn synthesis, allowing programs to evolve over multiple prompts. Finally, it visualizes performance on a mini benchmark and exports artifacts for reuse.
Why builders should care
Code generation models often pump out unverified code snippets, leaving developers to manually check correctness and safety. This approach automates rigorous stages that most builders handle themselves: syntax verification prevents broken code, static safety catches potential risks, and unit-test validation ensures functional correctness. Reranking multiple outputs by test results means fewer bugs slip through, which can save time and reduce debugging costs. Supporting multi-turn synthesis lets developers build more complex workflows interactively rather than rely on single-shot code generation.
The practical takeaway
This end-to-end workflow lays out a ready-to-implement method for improving code generation reliability. Builders can embed these validation layers to tighten post-generation quality control, making AI-generated Python functions more production-viable. Reranking by test outcomes encourages generating multiple alternatives and selecting the best one automatically. Saving verified code and tests as reusable artifacts further supports continuous integration pipelines or collaborative development environments. Overall, it shifts AI coding from draft output toward reliable, test-driven programming assistance.
What to watch next
Look for growth in frameworks combining language models with comprehensive validation steps beyond simple code completion. More toolkits may emerge focused on automated safety and correctness for AI programming models. Experimentation with prompt design and multi-turn interactions will likely improve model reliability further. Also, tracking how these methods integrate into developer workflows or CI/CD pipelines will reveal practical adoption. Finally, see whether reranking approaches like this become standard for production-grade code generation systems.
AI Quick Briefs Editorial Desk


