The KV Cache Compression Race: TurboQuant vs OSCAR vs EpiCache
What changed
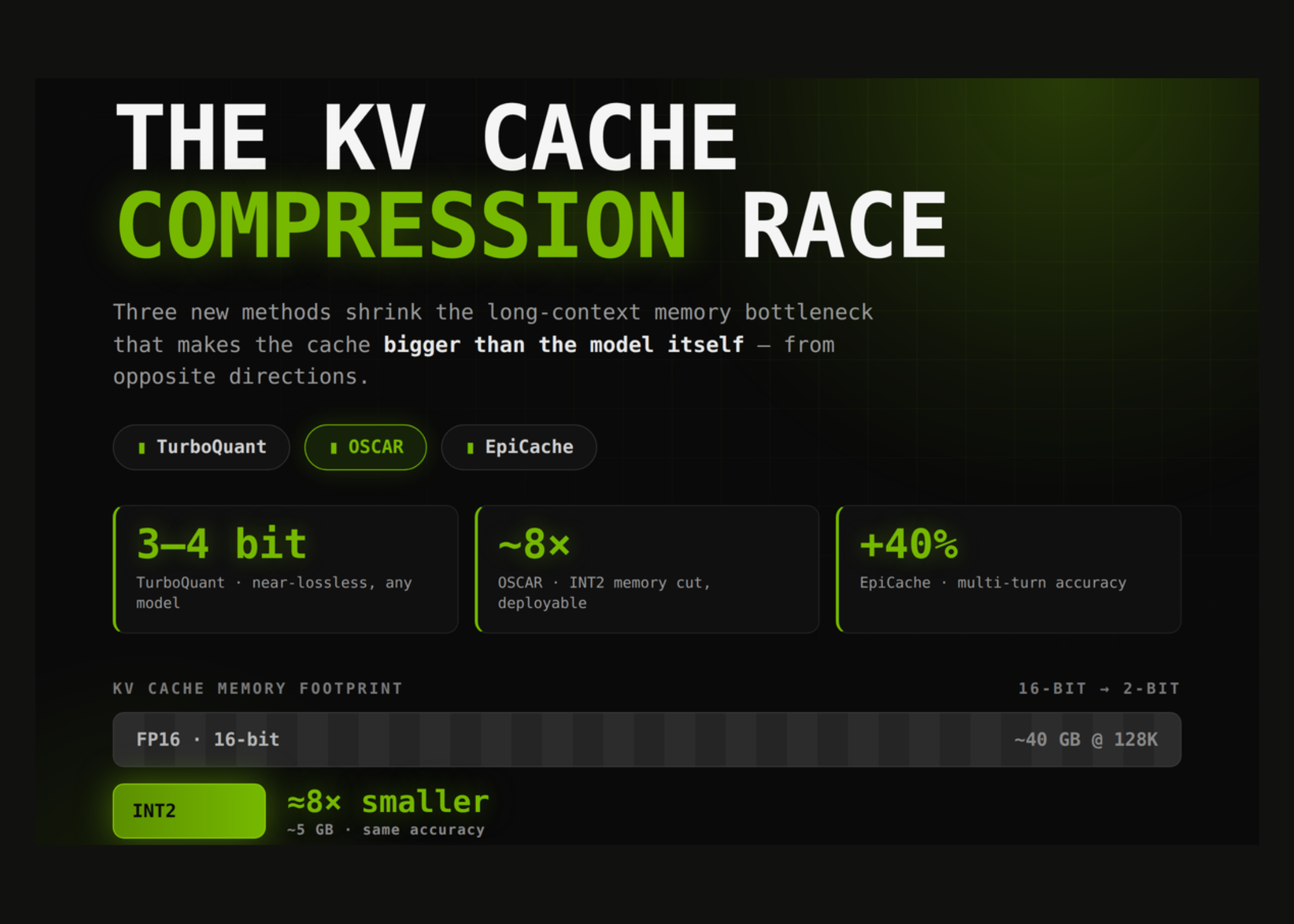
The memory footprint of long-context AI models is increasingly dominated by the key-value (KV) cache, surpassing the size of the model weights themselves. This shift creates a new bottleneck for deployment and inference efficiency. Three recent advances—TurboQuant, OSCAR, and EpiCache—target this memory challenge with different compression strategies, improving how models handle extended contexts without ballooning hardware costs or latency.
Why builders should care
Operators building or scaling AI systems with long contexts face high RAM and storage demands due to the KV cache size. Existing solutions often scale poorly, forcing tradeoffs between context length and performance. TurboQuant compresses the KV cache by quantizing tensors with minimal precision loss. OSCAR applies a specialized sparse approximation to the cache, cutting memory without hurting model accuracy. EpiCache offers an adaptive approach that segments and compresses cache entries dynamically. Together these tools reduce the memory strain, lowering hardware requirements and enabling longer context windows without proportional cost hikes.
The practical takeaway
For engineers, the promise lies in combining these techniques to optimize memory consumption without killing throughput or accuracy. While each method has distinct tradeoffs—TurboQuant excels in fast quantization, OSCAR balances sparsity and fidelity, and EpiCache adapts to workload patterns—they are more complementary than interchangeable. Adopting a hybrid compression pipeline lets teams squeeze more value from existing GPU or TPU resources and supports the growing appetite for ultra-long context tasks, such as legal or scientific document analysis.
What to watch next
The near future will show if these compression techniques become standard parts of AI infrastructure stacks or remain niche optimizations. Tracking which approaches gain adoption by cloud providers, open-source frameworks, and large model-serving platforms will reveal real-world performance impacts. Also watch for new tooling integrating these compression algorithms automatically during inference. Compression advances could pressure hardware vendors to rethink memory architecture and pricing. The winner in KV cache compression won’t be just the most aggressive reducer; it will be the most seamlessly deployable and flexible solution.
AI Quick Briefs Editorial Desk


