Using Lift to Turn Research PDFs into Structured JSON with Controlled, Schema-Guided Field-Level Evaluation
What changed
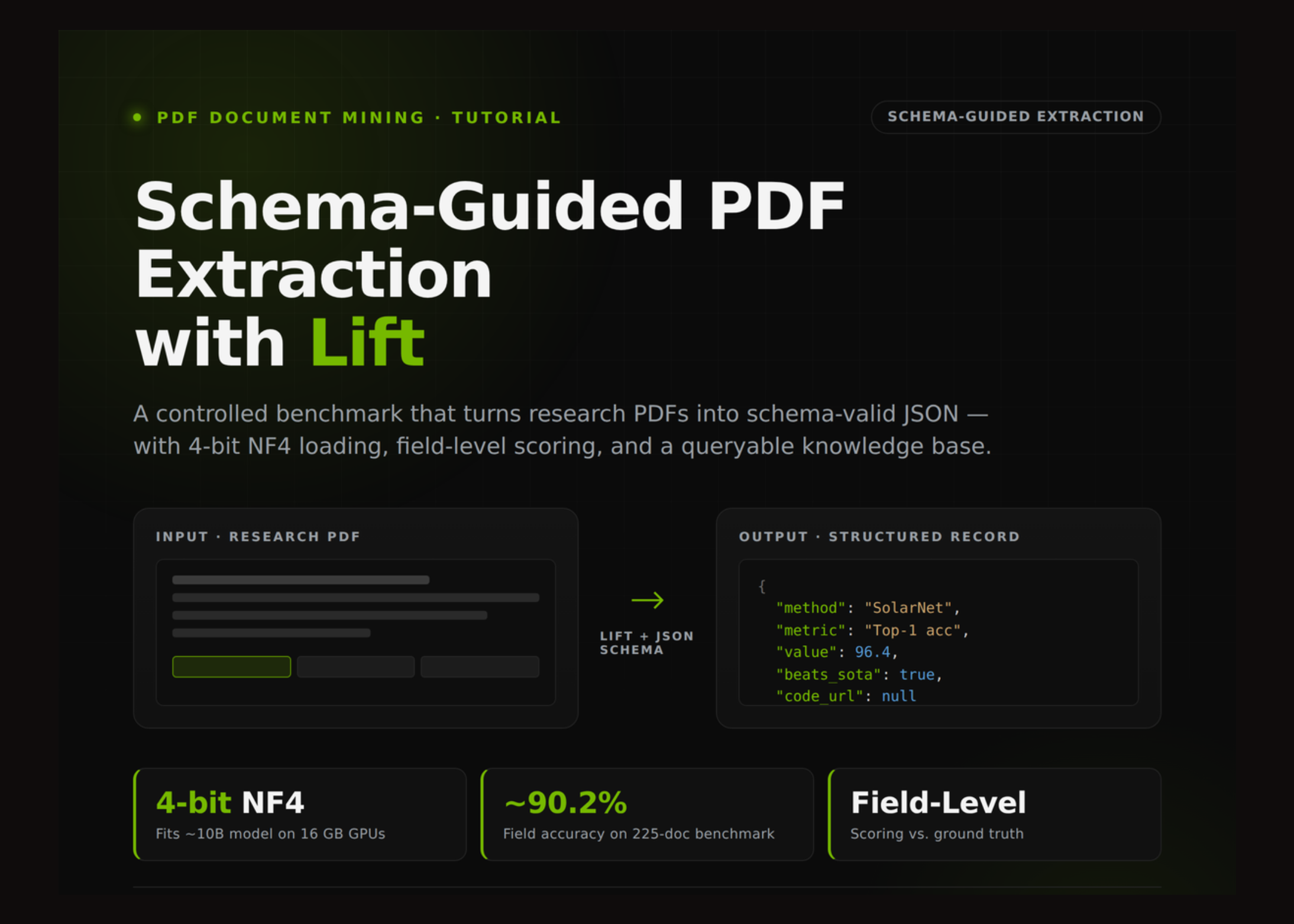
Lift introduced a workflow that converts research PDFs into structured JSON data with controlled, schema-guided, field-level evaluation. Instead of just parsing documents and spitting out raw outputs, this process evaluates each extracted field against known ground truth. It uses a Colab GPU environment, loads Lift in a compact 4-bit NF4 format, and generates synthetic research reports with intentional distractors to benchmark accuracy rigorously. The result is a repeatable, queryable knowledge base rather than one-off extraction experiments.
Why builders should care
Anyone running document ingestion, research summarization, or knowledge base automation faces the challenge of extraction quality. Most setups either lack fine-grained accuracy checks or rely on brittle demos that don’t scale. Lift’s approach forces explicit alignment to schema constraints and evaluates outputs field by field. This means operators get reliable error metrics and confidence data to tune workflows or flag failures. That level of control makes it easier to maintain quality when scaling PDF extraction pipelines across noisy data sources.
The practical takeaway
Implementing Lift’s workflow means more reliable automation when transforming complex reports into structured data for downstream uses like search, compliance, or analytics. The ability to generate synthetic data with controlled distractions also allows continuous testing against realistic document noise. Builders can now benchmark extraction routines rigorously and improve models iteratively instead of guessing at overall accuracy. Lift’s focused evaluation reduces the risk of garbage data propagating through knowledge bases, cutting operational overhead and error remediation.
What to watch next
The next key step will be Lift’s broader compatibility and integration with popular document processing pipelines and large language model frameworks. Watch for improvements in real-world PDF complexity handling beyond synthetic distractors and schema flexibility adjustments—for example, to accommodate changing research report standards. How Lift’s controlled scoring scales when applied to multi-source document fleets also matters; this will define its practical value as a tool for production ML ops in knowledge-intensive industries.
AI Quick Briefs Editorial Desk


