The Statistics of Token Selection: Logits, Temperature, and Top-P Walkthrough
Quick take
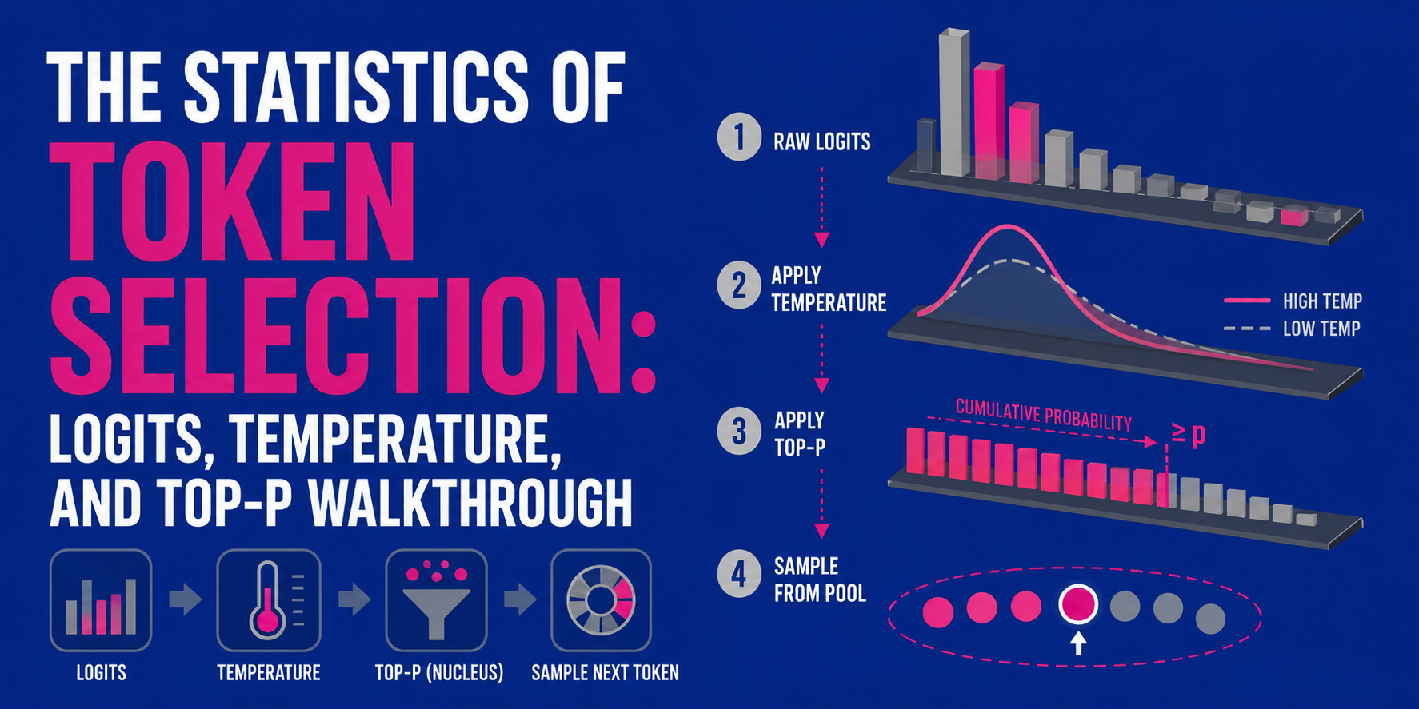
Language models like GPT pick their next word based on a complex statistical game involving logits, temperature, and sampling strategies like top-p. Logits are the raw scores the model assigns to each possible token before turning them into probabilities. Temperature adjusts the randomness of token selection—lower values make the model conservative and repetitive, while higher values encourage diverse, creative outputs. Top-p sampling narrows the choice to a subset of tokens that collectively hold a probability mass threshold, ensuring only the most plausible tokens are considered but still allowing some unpredictability.
These mechanics directly impact how coherent, relevant, or creative the output feels. Operators tuning these parameters balance between safe and sensible completions and surprising, novel ones. The choices influence how an application handles everything from chatbots to content creation, affecting user trust and engagement.
Why it matters
Understanding logits, temperature, and top-p is crucial for anyone building or deploying language models effectively. Setting temperature too high might produce unrelated or incoherent text, which can confuse or frustrate users. Too low means bland, stiff responses with less genuine engagement. Top-p sampling offers a more targeted control, focusing generation on tokens that are probable enough to keep coherence but variable enough to avoid repetition.
For businesses, tweaking these parameters can shape customer experience and brand voice. For developers, it informs how to strike a practical balance between response diversity and reliability, especially in conversational agents or automated writing tools. Without this knowledge, operators risk outputs that either fail to satisfy or go off the rails, impacting trust and adoption.
AI Quick Briefs Editorial Desk


