Liquid AI Ships LFM2.5-230M with llama.cpp, MLX, vLLM, SGLang, and ONNX Support for On-Device Inference
What it does
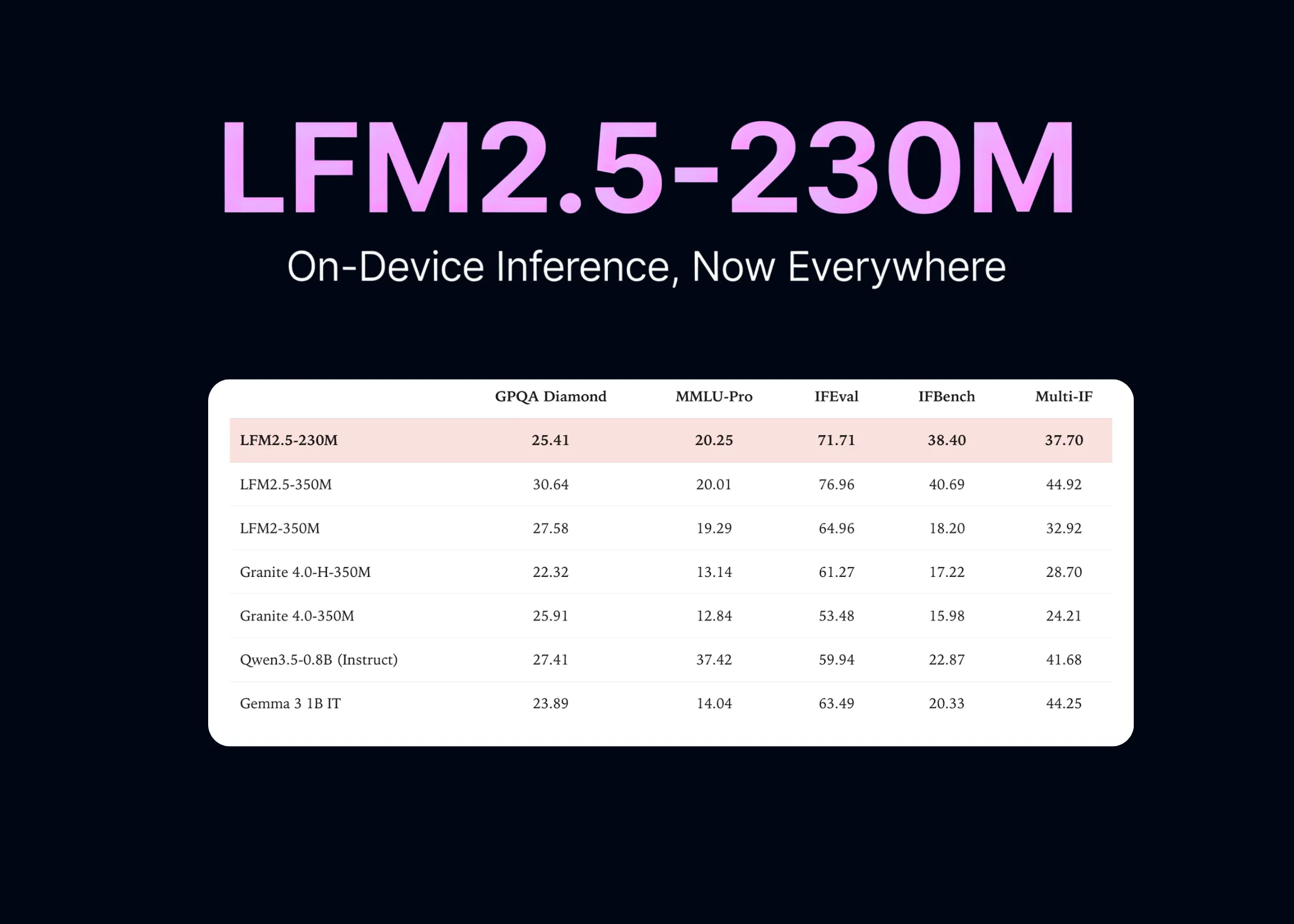
Liquid AI launched LFM2.5-230M, its smallest open-weight language model to date, with 230 million parameters. This model runs entirely on-device and achieves 213 tokens per second on a Galaxy S25 Ultra smartphone and 42 tokens per second on a Raspberry Pi 5. LFM2.5-230M is built on the LFM2 architecture and focuses on tasks involving tool use and data extraction. It supports popular frameworks and runtimes including llama.cpp, MLX, vLLM, SGLang, and ONNX, providing flexibility for different on-device AI workloads.
Why it matters
On-device AI is critical for applications demanding low latency, data privacy, and reduced cloud costs. The LFM2.5-230M model targets these requirements by enabling practical deployment on modest hardware like smartphones and single-board computers. Achieving faster inference speeds on devices as constrained as the Raspberry Pi 5 strengthens local AI use cases in edge and IoT environments. Additionally, LFM2.5-230M outperforms larger models such as Qwen3.5-0.8B and Gemma 3 1B in instruction-following tasks, demonstrating that bigger models are not always better when it comes to specific operational goals like tool interaction and extracting structured information.
Who it is for
This release is especially relevant for developers and operators building AI-powered tools that require embedded intelligence without relying on cloud connectivity. It suits mobile app developers, IoT device makers, and companies aiming to reduce cloud dependency or improve privacy by keeping inference local. Investors and AI infrastructure providers should also watch models like LFM2.5-230M, which pressure the market for efficient, on-device options capable of performing complex instructions with fewer resources.
The catch
While 230 million parameters is small compared to many publicly known models, it still requires optimization and fine-tuning to extract the best performance on limited hardware. The model’s niche focus on tool use and data extraction may limit its versatility for general-purpose tasks, potentially requiring complementary solutions for broader AI applications. Also, practical deployment will depend on the maturity and compatibility of the supported runtimes like llama.cpp and ONNX in specific environments.
What to watch next
Look for real-world benchmarks that test LFM2.5-230M beyond token throughput, focusing on task accuracy and robustness in production settings. Monitor how the open-weight model ecosystem evolves, especially compatibility improvements with runtimes and developer tooling. Watch for additional models targeting on-device AI with efficient architectures that challenge the assumption that bigger always means better and continue shifting AI power toward the edge.
AI Quick Briefs Editorial Desk

