Fine-tuning Language Models on Apple Silicon with MLX
What changed
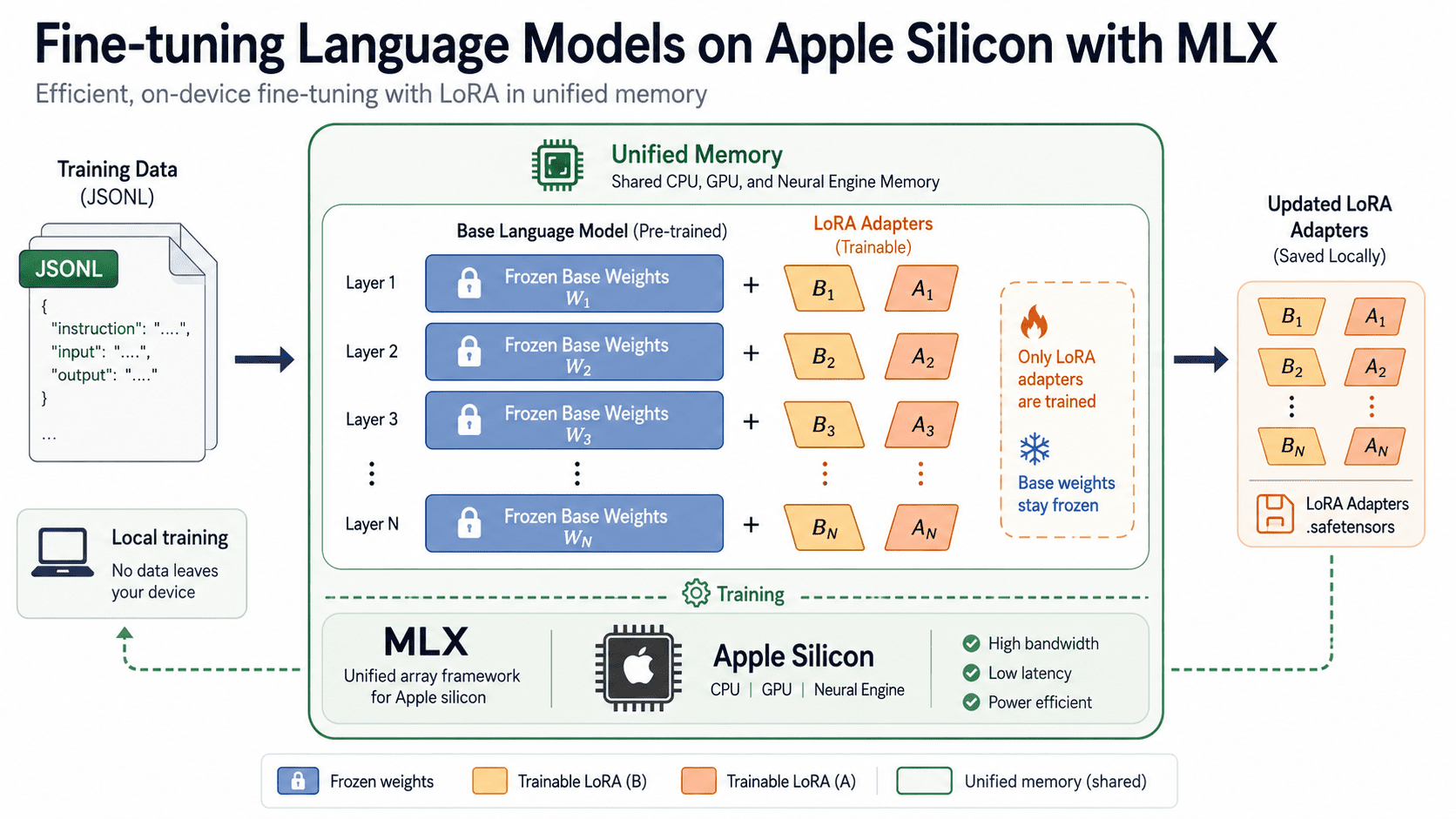
MLX now makes fine-tuning open-source language models feasible on Apple Silicon Macs without relying on expensive cloud GPUs. Thanks to optimized tools and the performance boost of Apple’s M1 and M2 chips, users can customize models locally using modest hardware. MLX handles technical overhead, letting developers focus on adapting language models for specific tasks or datasets.
Why builders should care
Local fine-tuning cuts costs and removes cloud dependencies, a big deal for developers, startups, and small teams who need tailored NLP models but lack access to costly cloud infrastructure. Running on Apple Silicon also improves privacy by keeping data on-device rather than sending it to third-party servers. This shifts more AI training and tuning power into the hands of users with relatively accessible hardware.
The practical takeaway
MLX lowers the barrier to entry for fine-tuning language models, enabling practical customization for applications like chatbots, domain-specific content generation, or data analysis without significant cloud budget. It forces a rethink of when and where model fine-tuning happens, potentially accelerating AI prototyping and deployment cycles on personal devices. However, the size and complexity of models remain limited by Apple Silicon’s RAM and processing capacity compared to specialized GPUs.
What to watch next
Track how widespread local fine-tuning grows among Mac users and whether MLX extends support to larger models or more hardware variants. Watch for competitors enabling similar workflows on other edge devices. Also, see if cloud providers respond by lowering prices or offering integrated hybrid solutions to keep up with local fine-tuning trends.
AI Quick Briefs Editorial Desk


