Context vs. Memory Engineering in Agentic AI Systems
What changed
Agentic AI systems that rely on Compression on Arrival tools have a critical update: output compression should happen immediately after a call returns, not delayed until the memory window fills. This timing shift challenges prior designs where data accumulated first, then compressed in batches.
Why builders should care
Fine-tuning when compression happens affects both agent performance and system efficiency. Compressing outputs right after each call avoids losing valuable context early and reduces lag in updating short-term memory. This leads to faster response times and more accurate, relevant agent behavior in long-running workflows.
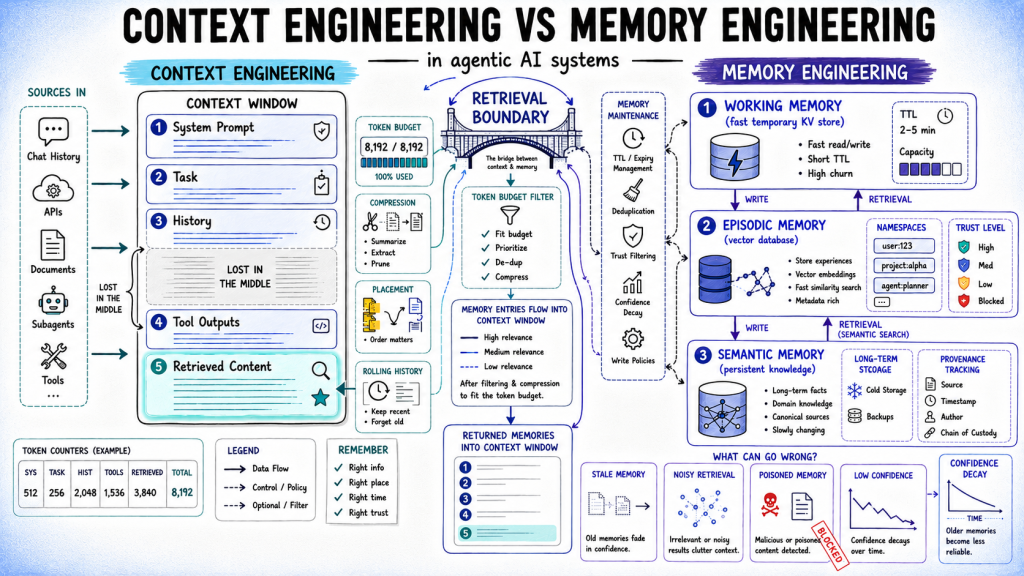
Memory engineering in agentic systems is about managing what the agent “remembers” versus what it can access in context. This update clarifies that handling output data too late risks sloppy memory states, forcing builders to rethink how they balance context windows with ongoing memory compression.
The practical takeaway
For developers creating conversational agents or multi-step AI workflows, this means prioritizing immediate compression of outputs rather than batch compressing after a memory window fills. It tightens control over agent memory, improving both speed and result quality. Operators should revisit existing agent architectures where output compression still waits for a full memory window, as this can introduce unnecessary delays and context drop-offs.
The shift also pressures tool and API providers to expose more granular control over compression timing. Builders need to avoid workflows that let memory buffers grow unchecked before compression, which bloats resource usage and complicates debugging.
What to watch next
Watch how popular agent platforms and frameworks adapt their memory management defaults. Tools that allow dynamic compression triggering immediately after output returns will gain operational edge. Also, monitor if this drives new best practices or standard patterns for managing agentic AI state.
Because memory and context handling directly impact cost and performance at scale, investors and operators should track whether this approach reduces cloud compute expenses and accelerates deployment timelines. Streamlined memory engineering may push the market toward leaner, more responsive agent systems.
AI Quick Briefs Editorial Desk

