NVIDIA cuTile Python Tutorial: Building Tiled GPU Kernels for Vector Addition, Matrix Addition, and Matrix …
What changed
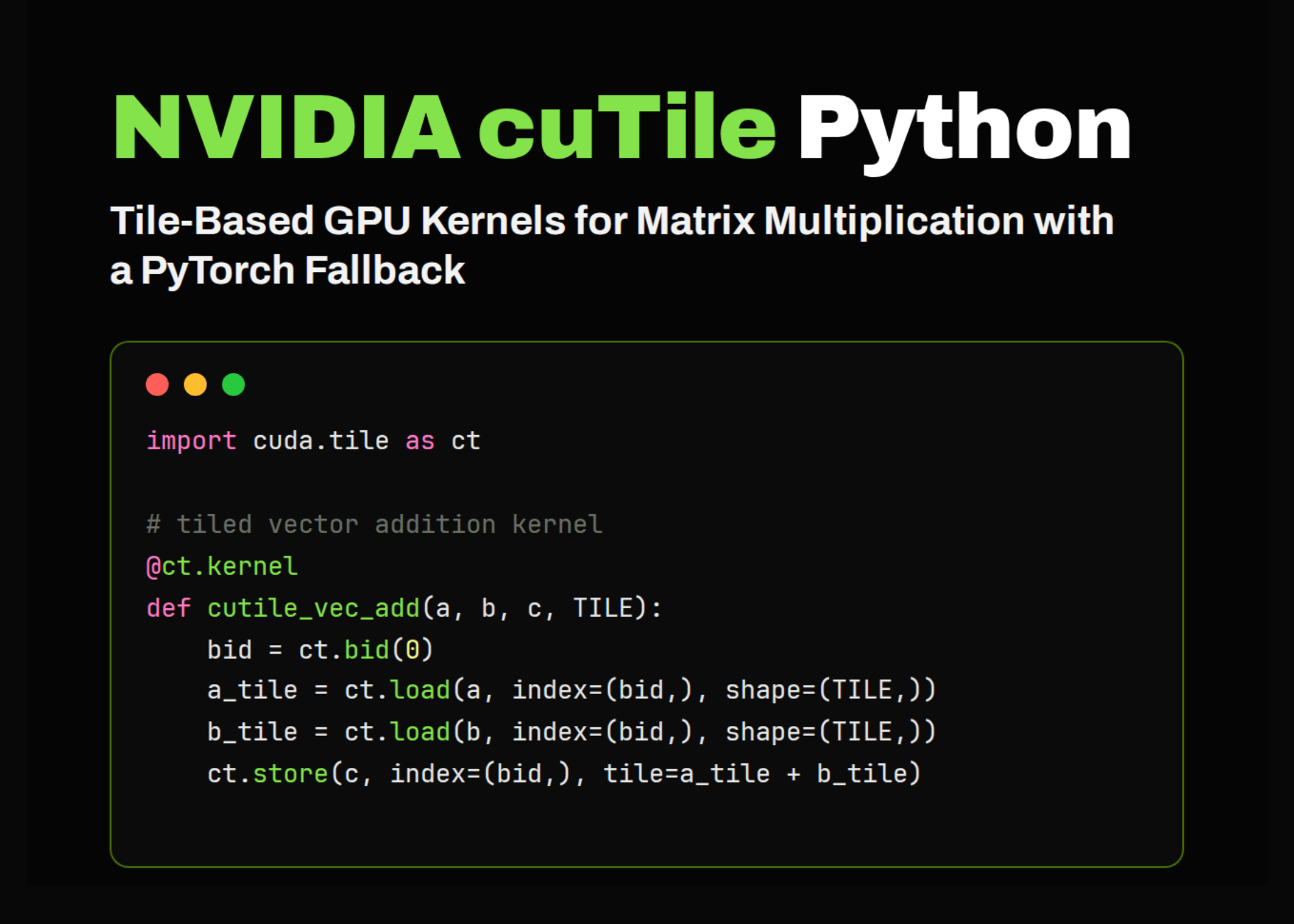
NVIDIA released a Python tutorial for cuTile, a tile-based GPU programming interface designed to write CUDA-style kernels easily in Python. The tutorial targets hands-on application in a Colab environment and guides building tiled implementations of vector addition, matrix addition, and matrix multiplication kernels. It also integrates PyTorch fallbacks for smooth execution and compares results to validate correctness. Benchmarking median runtimes at each development stage offers practical performance insights.
Why builders should care
Tiling is critical to optimizing GPU workloads by breaking large datasets into manageable chunks for better memory access and parallel processing. The cuTile Python approach simplifies writing CUDA kernels without dropping into lower-level C++ or CUDA C syntax. Running this fully in Colab lowers barrier to entry, making it easier for developers and researchers to prototype and tune high-performance GPU code with immediate feedback. Combining tiled kernels with PyTorch fallbacks ensures usability across hardware and libraries, important for hybrid workflows or fallback scenarios.
The practical takeaway
Builders get a clear workflow to speed up GPU kernel development and benchmarking directly in Python. The tutorial shows how tile-based strategies improve performance for fundamental operations in linear algebra and vector math, common in AI workloads. For teams investing heavily in GPU compute or needing custom kernel optimizations, this approach saves time versus traditional CUDA C development. Early runtime benchmarks help prioritize optimization targets. Plus, it makes GPU programming more accessible by using popular Python and PyTorch tools.
What to watch next
The next step is to observe how widely developers adopt cuTile for larger, more complex kernels beyond dense linear algebra. Updates might expand tile sizes, scheduling flexibility, or integration with other ML frameworks. Watch for improvements in automated tuning and profiling tools to complement the cuTile Python interface. Enterprise and research users will push for support on newer GPUs and heterogeneous systems. NVIDIA’s approach pressures competing GPU tooling to simplify kernel development without sacrificing control or speed.
AI Quick Briefs Editorial Desk


