Parallax: A Parameterized Local Linear Attention That Keeps Softmax and Adds a Learned Covariance Correctio…
What changed
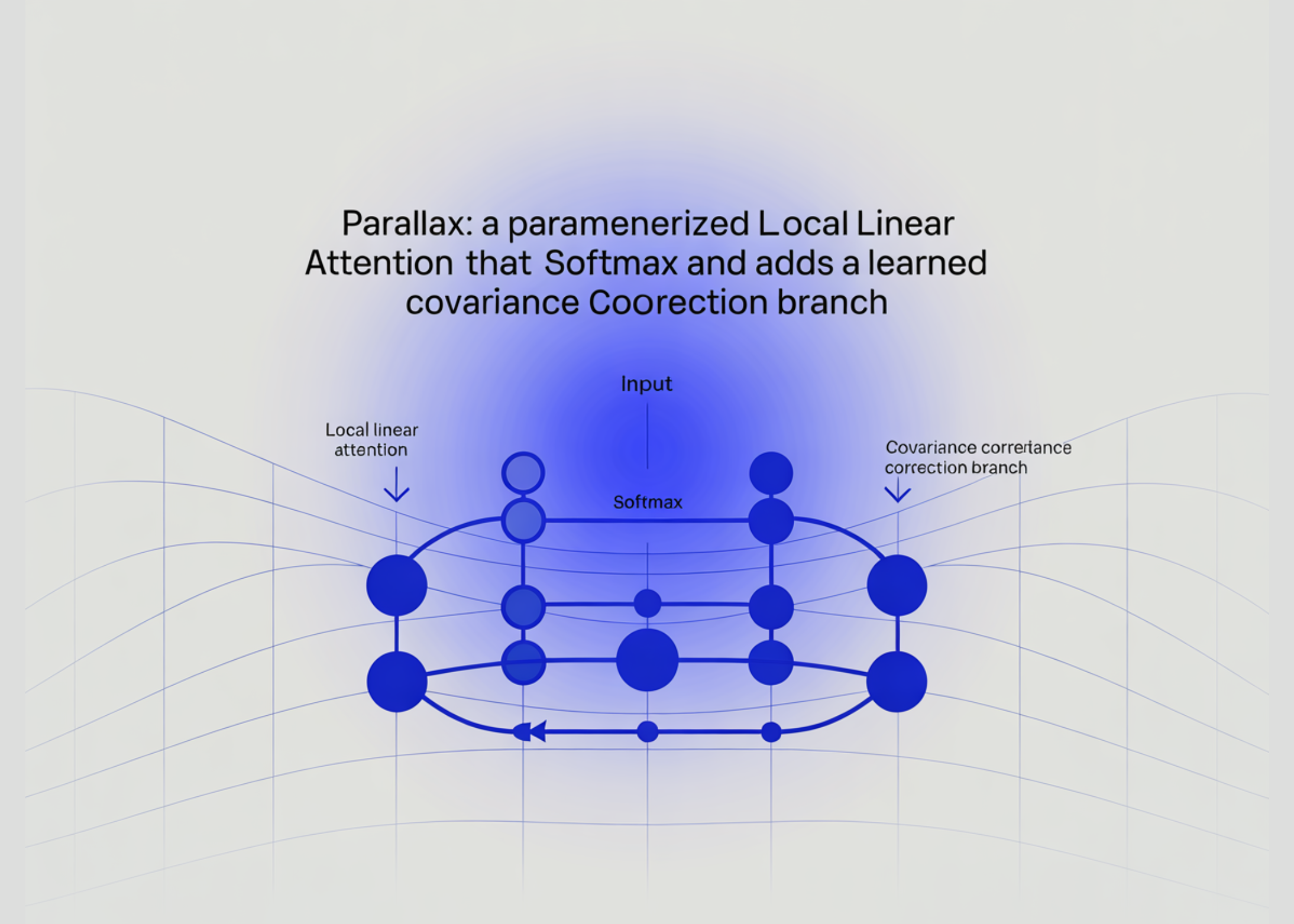
Parallax updates Local Linear Attention (LLA) by replacing its per-query solver with a learned projection layer. This technical change doubles arithmetic intensity and retains softmax, which standard LLA methods lose. The new approach adds a learned covariance correction branch that improves the attention mechanism’s ability to model interactions between tokens.
Why builders should care
For developers working on transformer models, Parallax offers a practical way to boost efficiency and output quality simultaneously. By integrating a learned covariance correction, it reduces reliance on expensive per-query computations while keeping softmax normalization. This means faster training and inference at scale when working with mid-sized models around 0.6B and 1.7B parameters, without sacrificing perplexity—a direct measure of language model performance.
The practical takeaway
Parallax presses for rethinking how attention is implemented in transformers to gain speed and accuracy simultaneously. Operators running or tuning medium-sized LLMs can expect better perplexity scores with roughly the same computational budget. This translates to lower costs or better model quality for enterprises deploying language models in production environments. The approach is especially relevant where softmax normalization remains crucial but currently bottlenecks efficiency.
What to watch next
Watch for open-source implementations or integration of the Parallax approach into popular transformer frameworks. Further research will clarify how well the covariance correction adapts across different language tasks or larger-scale models. Investors and AI infrastructure providers should note if this method pressures existing attention computation techniques, potentially shifting optimization priorities for memory and compute usage.
AI Quick Briefs Editorial Desk


